

From Hackathon to Enterprise: Pushing the Boundaries of Self-Hosting AI
I’ve been fascinated by the potential of GPT-4 class models for a while now. While these capabilities have been accessible through APIs from Anthropic and OpenAI, I think it’s a game-changer to be able to run a model of this class on your own hardware and study its abilities and properties. In my opinion, GPT-4 class models are the key to having AI systems make reliable, speedy superhuman decisions or insights. And self-hosting is the missing step that makes research, reliability and privacy assured.
With the recent release of Llama 3.1 405B, this self-hosting capability is finally within reach. This isn’t just another model release — it’s the democratization of superintelligence. In my view, enterprises across industries are poised to unlock transformative use cases with on-premises hosting of this computational behemoth. From hedge funds iterating on proprietary trading strategies to pharma giants accelerating drug discovery to codegen agents and copilots for proprietary codebases, the potential applications are as diverse as they are profound.
Imagine an AI that assists a hedge fund trader by autonomously creating and back testing different strategies given a design doc full of ideas. Or envision a system that can redesign supply chains in real-time, adapting to global disruptions faster than any human team could. These aren’t far-future scenarios. They’re the immediate possibilities that Llama 3.1 405B brings to the table.
In this article, I’ll take you behind the scenes of my recent hackathon victory with Llama 3.1 405B and invite you to think about how to transform my rapid prototyping experience into robust, enterprise-grade deployments. Whether you’re a CTO of a Fortune 500, a quant at a hedge fund, or a tech leader at a unicorn SaaS, I hope you find valuable ideas for your proprietary AI strategy in this article.
Let’s dive in and explore how to install Llama 3.1 405B on a VM and load test its performance. Out of scope of this article is how to leverage its capabilities to create genuine competitive advantage in your domain, but I’m here and open to inspiration for future articles!
Genesis
This awesome initiative was inspired by the AGI House SF Emergency Hackathon for Llama3 405B, where a team of 4 other hackers and I got Llama 3.1 405B up and running in just a few hours on an 8xA100 box, and took the first prize.
What this Post is About
This post outlines the steps you need to take to run Llama 405B (quantized FP8) on a single 8XH100 or 8XA100 machine in the cloud and run inference. It will have a lot of technical steps. Then there’s also going to be a load test comparing Meta’s own FP8 version to the version published by Neuralmagic using a different quantization process.
What is quantization and what is FP8?
Quantization in AI is the process of reducing the precision of the numbers used in a model, which helps to decrease memory usage and speed up computations, enabling more efficient model deployment.
In the AI world, numerical precision formats like bf16 and fp8 dictate how much computing power is needed. bf16, or Brain Floating Point 16-bit, is a format that uses 16 bits per number to strike a balance between accuracy and performance, generally requiring 16xH100 GPUs for effective inference with Llama 3.1 405B. On the other hand, fp8, an 8-bit Floating Point format, is designed for high efficiency, achieving similar performance levels on just 8xH100 GPUs. This makes fp8 an appealing choice for systems where minimizing hardware while maintaining strong performance is key.
Precision and Range
- bf16: The combination of 7 mantissa bits and 8 exponent bits provides a good balance of precision and range, making it suitable for both training and inference phases in machine learning.
- fp8: With around 2 mantissa bits and fewer exponent bits, offers less precision and a shorter numerical range. It's typically optimized for inference rather than training, focusing on scenarios where model size and speed are more critical than utmost accuracy.
Steps to Setup Llama 3.1 405B FP8 on a single 8xH100 VM
Using Ubuntu 20.04 or 22.04, install Llama 3.1 405B by following these steps.
Once installed, running the two models tested “meta-llama/Meta-Llama-3.1–405B-Instruct-FP8” and “neuralmagic/Meta-Llama-3.1–405B-Instruct-FP8” is really as simple as
vllm serve $MODEL_NAME --tensor-parallel-size 8 --host 0.0.0.0 --port 8000
Incredible how easy it is! Just like running Apache, as long as you have the right hardware.
Load testing Llama 3.1 405B FP8 using locust
Before describing the load tests below, code and raw results from load testing can all be found here.
Locust is an excellent open-source load testing library where you can configure diverse user behavior in Python and then run load tests at scale using a really straightforward web interface that runs locally. So it’s straightforward, for example, to emulate hundreds of users trying different prompts against your LLM server at the same time. Locust also does a pretty good job of collecting custom metrics, so with some configuration we are able to record tokens in, tokens out, and tokens per second by prompt.
What are we load testing?
We will be obtaining tokens per second (tok/s) and response times for prompts of various input and output lengths. We test both the meta-llama/Meta-Llama-3.1–405B-Instruct-FP8 as well as the neuralmagic/Meta-Llama-3.1–405B-Instruct-FP8 variants of Llama 3.1 405B.
Why tokens per second (tok/s) is a misleading metric by itself
Around the same time I was conducting this test, Sambanova made a public announcement about hosting Llama 3.1 405B BF16 and being able to serve it at 114 tok/s. Several model hosting providers seem to advertise performance in terms of tok/s. Unfortunately, on introspection, it becomes obvious that publishing a single tok/s metric for a model is a form of marketing sleight-of-hand. Because tok/s varies immensely based on number of input tokens and number of output tokens. I demonstrate later on that prompt complexity has nothing to do with response times or throughput! While I hope that the AI market research firm that conducted the analysis in the case of Sambanova used a heterogenous set of “representative” prompts to get that combined tok/s number, they do not seem to reveal what are those prompts are. Hence we do not know in what kind of production workload how many tokens per second are produced, and what response times really are. I look forward to running Sambanova’s endpoint through my load tests outlined here and reporting back. Is it really 8x the speed of self-hosting? I doubt it, but need to validate.
Diversity of response speeds for different prompt types
This diversity of response speeds for different prompt types is demonstrated below. When serving meta-llama/Meta-Llama-3.1–405B-Instruct-FP8, a simple prompt to classify the sentiment of a short paragraph as positive, neutral or negative can achieve a throughput of 6 tokens per second, and you can get a response back in 155 ms +- 1ms.
results table for testing llama3.1 405B on 8xH100 with 1 user, temp 0
An ensemble of short prompts returns an average tok/s of 14.47 with Meta’s quantized model and 15.41 with Neuralmagic’s quantized model.
Long input prompts (100K+ input) generate between 0.31 and 2.57 tok/s and take 2–3 minutes to resolve.
Prompt complexity doesn’t matter, just number of input tokens and output tokens
Next we look into prompt complexity. Here we will try two forms of equally long prompts, but one that is easier to understand than the other. We found in both cases that the LLM took the exact same amount of time regardless of the complexity of the input message. This was surprising to me.
Ex 1: classify vs classify-hard
Here we ask the llm to classify two testimonials about a job:
classify starts with: “I’m absolutely thrilled with my new job! The work environment is fantastic, my colleagues are incredibly supportive, and I’m learning so much every day.”
classify-hard starts with: “My new job is a complex mix of emotions and experiences. The work environment is intense, with high expectations and tight deadlines.”
In both cases the LLM is asked to classify the testimonial as positive, negative or neutral. In both cases, the number of input tokens is exactly 155, and the results in terms of speed of inference are the same. The response rate is around 5.5 tok/s, and the response time is around 180ms +- 1ms.
Ex 2: happy-dog-simple vs happy-dog-complex.
Here the model is asked to produce writing of upto 100 tokens with the following prompts. This is similar to the first example, but more focused on output tokens.
happy-dog-simple: “Write about a happy dog playing in a big green park on a warm summer day.”
happy-dog-complex: “Elucidate canine euphoria exhibited amid verdant expanses during sultry conditions.”
Here both prompts return output at 17.8 tok/s and have a response time of 5628 ms += 20ms.
Discovery: System prompt matters a lot with Llama. It’s pretty much Garbage Out without a system prompt regardless of how straightforward the request. Always use a system prompt with Llama 3.1 405B FP8!
When using the text completions endpoint (/v1/completions) instead of the chat completions endpoint (/v1/chat/completions) without a system message, frequently even the simple classification of a statement as positive, neutral or negative would return a 0 word response, or the beginning of a longer sentence with a fragment like “I”. At a higher temperature it would often answer correctly 0% of the time even though the prompt has the explicit instruction “ Single word response only”. This unexpected behavior resolved itself completely with the simple system prompt “I am a helpful assistant”. Hence the recommendation to always use a system prompt with this model, even if it’s really simple.
Tok/s at higher user count on a ensemble of short prompts
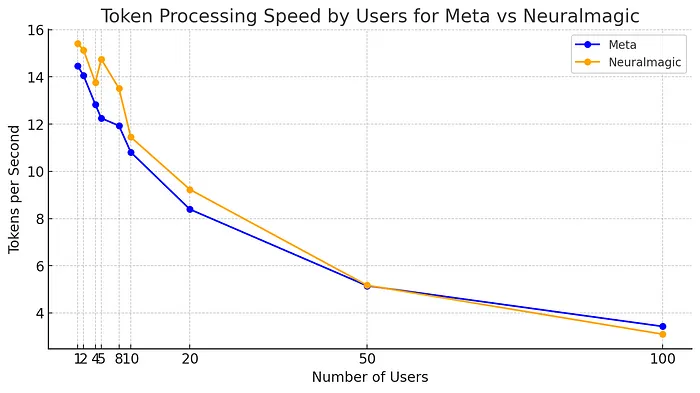
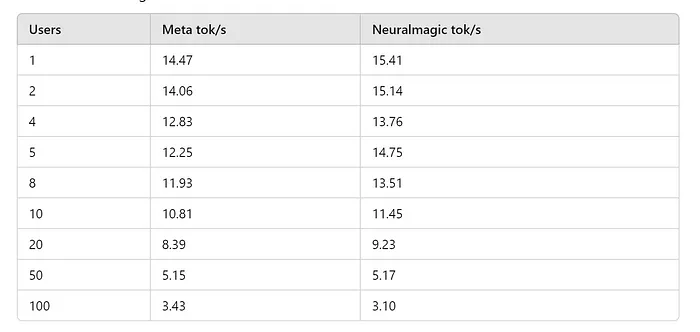
These are users directly hitting the LLM, in real world cases agents and human users are both bottlenecked by I/O from external APIs and events. So, in practice, a good rule of thumb is you can multiple the number by 4 for agents and 10 for human chat users. So 20 agents or 50 users can hit this machine constantly and expect pretty performant throughput.
Note: vLLM consistently warned there was a resource memory leak when shutting down the meta-llama/Meta-Llama-3.1–405B-Instruct-FP8 model.
Costs
All testing was conducted using a FluidStack 8xH100 machine with 252 cpus and a 6.3 TB ephemeral hard drive purchased through brev.dev. The machine was spun up and managed using brev.dev’s awesome tooling. The cost of this machine was $33.50 / hr on-demand. So, around $24,120 per month. This is 1/3 the price found at other on-demand vendors, so definitely look into using brev.dev when experimenting!
Altogether the setup load testing described in this article took around 20 hours.
Conclusions
- The neuralmagic model is definitely faster, and seems to return identical outputs for these prompts. Definitely use that over Meta’s quantized model if serving with vLLM.
- Ramping up to 5 concurrent users has no great effect in tok/s for each individual user and so that’s what you get at full performance.
- There’s only a mild slowdown on tok/s upto 10 concurrent users.
- Always use the system prompt with Llama 3.1 405B.
- If you accept my assertion above of 20 concurrent agents or 50 concurrent users using the system and getting the 10 tok/s performance for ensembles of shorter prompts like above, you see that the cost per agent per month is around $1200 and the cost per human is $482 when self-hosting on-demand. If I was buildling a proprietary copilot for my engineers, I could expect to support 50 engineers at top speed using one machine.
I couldn’t do any vibe checks or benchmarks on the output quality yet, but I’m optimistic about Llama 3.1’s RAG and codegen capabilities. I’ll be drilling deeper into codegen & code search load testing in one of my next posts. At least I now know what $25K per month hosting can get me using brev.dev and paying on-demand pricing! For a hedge fund, government institution or mega software corporation, these numbers may well work out!
What Subsequent Posts in this Series will be about
In no particular order, these are topics I wish to explore and blog about:
- How to run Llama 3.1 405B BF16 on 16 GPUs
- How to run popular benchmarks against it and what they mean
- Comparison with hosted Llama 3.1 405B at various providers — Fireworks, Together.AI, Amazon Bedrock, Sambanova, OctoAI etc
- How to test GPT-4 class models — load test and quality comparison with GPT4o, Claude 3.5 Sonnet
- How to do code generation using Open Source models
Open also to suggestions & collaborations — reach me on LinkedIn here.
Thanks
Must give a big shoutout to AGI House SF for their amazing initiative for hackers to test out Llama 3.1 405B on launch day. They get all the hackers to try out the latest tech on the day it comes out. When the siren calls, us first responders got to respond.
I want to give a huge shoutout to brev.dev, a subsidiary of NVidia, for hooking me up with the compute power for both the initial project and this follow-up blog post. Their support has been instrumental in making this happen.
I also want to thank tribe.ai for sponsoring this post. As a contractor with tribe.ai, I can attest to the fact that they’re the go-to firm for enterprise-grade AI solutions. The team is comprised of experts from diverse backgrounds, including top software engineering firms like Microsoft, Zynga, Amazon, OpenAI, Anthropic, and more. There’s a constant flow of knowledge and talent between tribe.ai and the top enterprise AI vendors, as well as between tribe.ai and the top startup incubators like Y Combinator. These revolving doors and proprietary channels facilitate the highest level of knowledge transfer and expertise. It’s an amazing community to be a part of!











